This page presents descriptions of some of the data projects I have been involved in.
Quality Prediction Based on Sensor Time Series Recordings
-
Challenge: A manufacturing company needed to analyze large volumes of time series data from production machines to understand if there are usable signals to predict the quality of final products. The challenge was finding meaningful patterns in the vast sensory data associated with single outcome labels, and ensuring the model’s interpretability for production engineers.
-
Solution: The project involved conceptualizing and implementing data pipelines to filter, connect, and integrate multiple data sources for machine learning model development. The processed data served to train
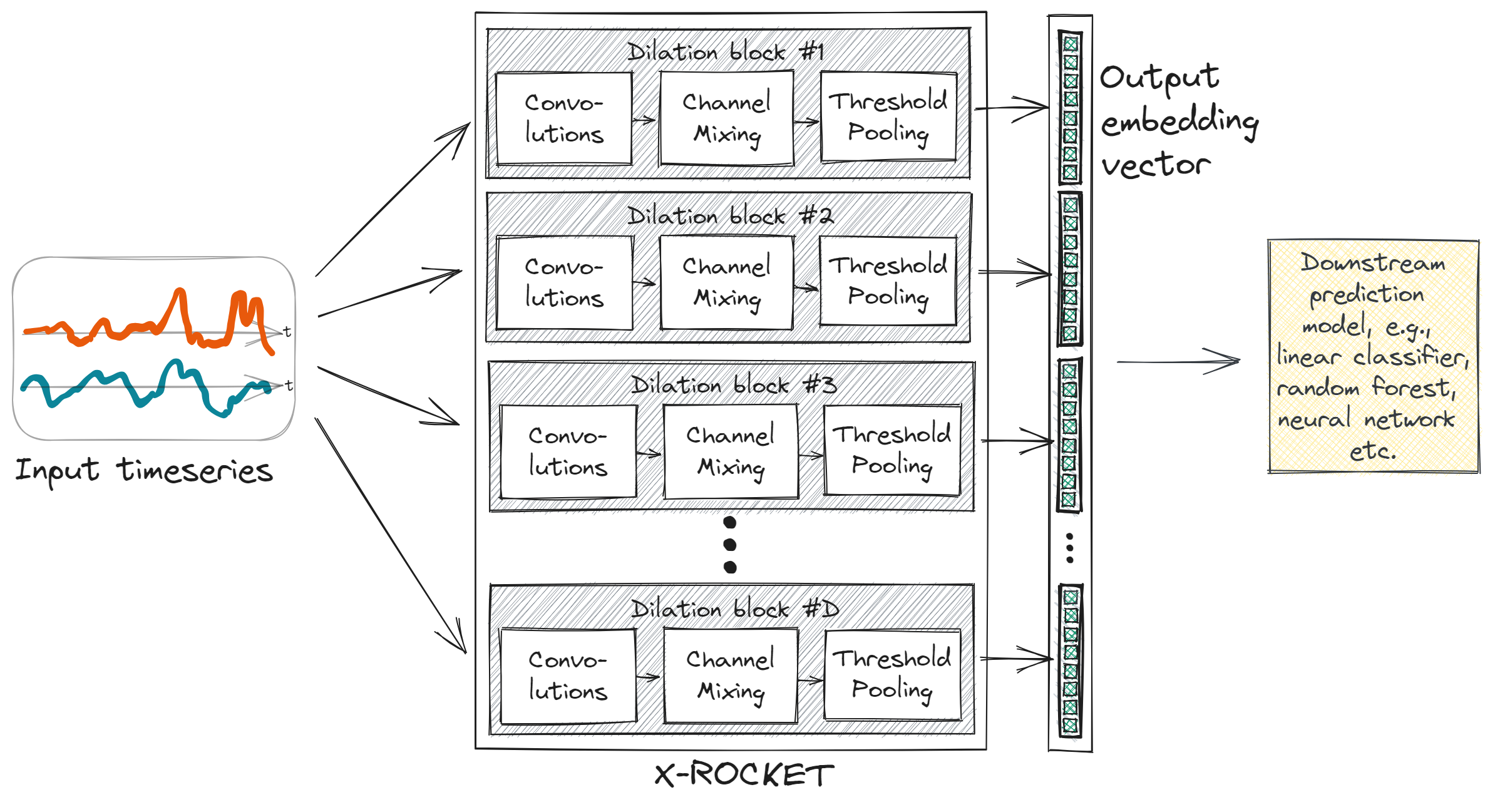
PyTorchneural network models, with multiple predictive models tested, including simple statistical approaches and deep convolutional neural networks. A strong emphasis was placed on explainable AI to ensure production engineers could interpret the model’s findings. Therefore, the state-of-the-art time series encoder model ROCKET was augmented to add explainability and provide insights into the driving signals and patterns. -
Impact: The project delivered actionable insights into production processes in the form of a ranking of the top 5 most important signals, ultimately helping engineers optimize operations and improve product quality. The development of the explainable ROCKET encoder model allowed for better adoption and understanding of the outputs.
Click for additional information
- Details and Links: For further details on the model architecture and implementation, refer to my three-part article series on the X-ROCKET architecture (Part 1, Part 2, and Part 3), and the corresponding code repository.
- Stack:
PyTorch,CNNs,ROCKET,git,Time series classification,explainable AI,Python,numpy,matplotlib
Visual Contamination Detection in Industrial 3D Printing
.jpg)
-
Challenge: In industrial additive manufacturing, identifying contamination during the printing process is critical to prevent machine damage and optimize productivity. The objective of this project is to automate the process monitoring by developing a computer vision algorithm that detects pollution of production machines from pre-installed infrared cameras in real-time. However, data heterogeneity across different machines and limited data availability posed significant challenges for building an effective monitoring system.
-
Solution: The project began with workshops conducted alongside domain experts to define the use case and evaluate the potential of machine learning in the production environment. Systematic data collection and pre-processing were guided to prepare datasets for model training, and we created a custom labeling tool to annotate image datasets for training. A ResNet convolutional neural network was developed in
PyTorchto detect machine contamination in real-time using computer vision, with data augmentation techniques applied to address data heterogeneity and limited data availability. The final model was containerized usingDockerwithFastAPIendpoints for deployment, ensuring seamless integration with the production machines. -
Impact: The project delivered a production-ready system capable of informing operators of potential faults in real-time with a success rate of 95%, preventing machine damage and reducing downtime.
Click for additional information
- Details and Links: For more information on the machine learning use case and the overall project, refer to the project pages of dida, Fraunhofer IPT, and BMBF. Additionally, details about the labeling tool created for the annotation of the image dataset can be found in my article, and the corresponding code repository.
- Stack:
PyTorch,Convolutional neural network (CNN),Docker,git,OpenCV,FastAPI,Computer vision,pytorch-lightning,ipywidgets,Python
Automated Question Answering via Document Retrieval
-
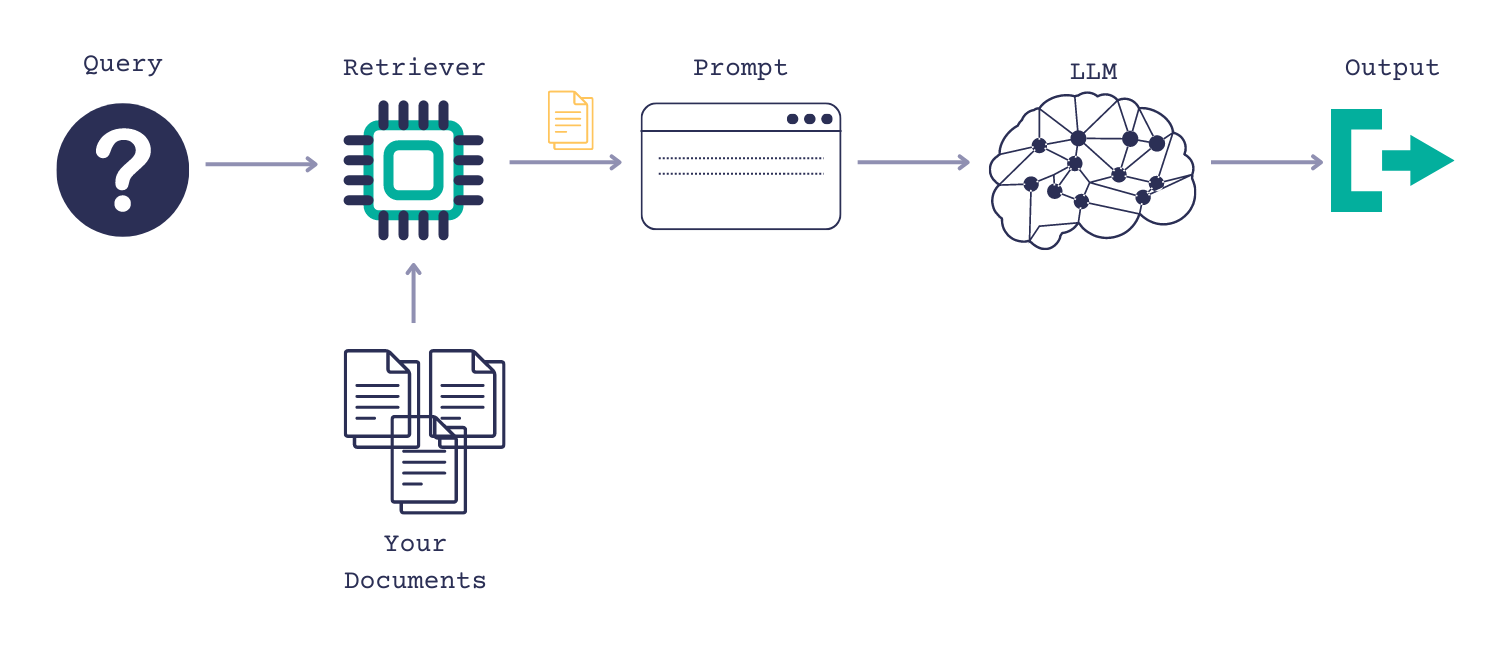
Challenge: Company knowledge is often scattered in internal documentation rather than accessible for employees through familiar channels. The project therefore aimed at creating a chatbot for question answering (QA) based on on internal documents into the communication platform used by the employees.
-
Solution: An initial demo was developed using extractive QA and semantic search to identify answers in internal documents. As the project evolved, the solution expanded to incorporate generative QA by integrating LLMs with retrieval augmented generation (RAG), allowing for more sophisticated and dynamic responses. The project team leveraged
huggingfaceandHaystackfor implementation. Additionally, a custom codebase was developed to connect to the Slack platform API, and regular updates on rapid NLP advancements were shared with the team to ensure alignment with the latest research and industry trends. -
Impact: The project successfully delivered a proof-of-concept, enhancing employee productivity by providing instant access to relevant information stored in the internal documentation base. The solution promises to streamline internal communication and provided valuable insights for future exploration of LLM-based QA solutions.
Click for additional information
- Stack:
huggingface transformers,haystack,LLM,document retrieval,semantic search,question answering,BERT,git,beautifulsoup,python,API
Estimation and Analysis of Variance Spillover Networks
-
Challenge: The project aimed to develop robust models for analyzing large-dimensional time series datasets as networks. A key challenge is to develop machine learnig methodology for multivariate time-series forecasting such that the parameters have an econometric interpretation when conducting rigorous statistical analysis.
-
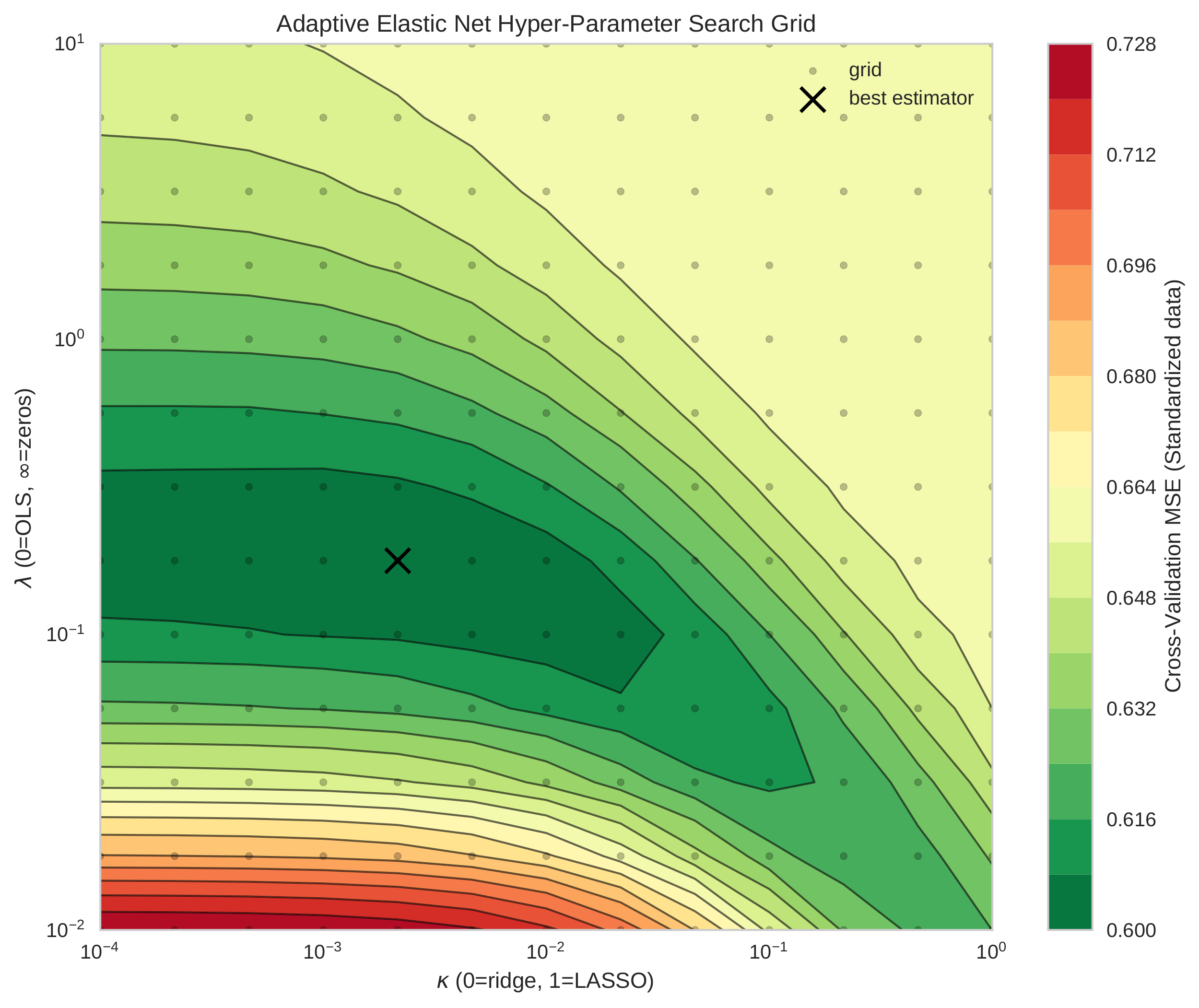
Solution: The solution involved acquiring financial time series data from
SQLdatabases and developing a custom data pre-processing pipeline to prepare the data for estimation over rolling time intervals. Object-oriented code leveragingscikit-learnandglmnetenabled the robust estimation and comparison of regularized statistical learning algorithms in VAR models with cross-validation. Extensive statistical analyses and visualizations usingstatsmodels,networkxandmatplotlibthen offered empirical insights that were recorded in academic research papers. -
Impact: The project successfully produced several research papers, including an acclaimed publication in Quantitative Economics. The developed methods and empirical findings significantly advanced the understanding of time series analysis and forecasting, particularly in network estimation and economic spillovers. The work continues to contribute to the field, with further papers under review.
Click for additional information
- Details and Links: For more information on the research papers and the underlying code repository, visit the research page and the GitHub repository. The first related research publication with Ruben Hipp is available in Quantitative Economics.
- Stack:
pandas,numpy,time series forecasting,scikit-learn,python,SQL,glmnet,econometrics,statsmodels,vector auto-regression,networkx,matplotlib,MS Azure
Police Search Success Prediction and AI Fairness Analysis
-
Challenge: Police searches in the UK were found to have inconsistent success rates and displayed signs of potential bias. The objective was to create a system to optimize search approval accuracy while minimizing discrimination.
-
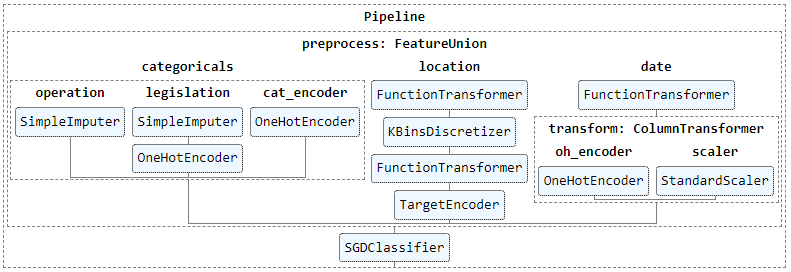
Solution: Using a tabular dataset of UK police data, I developed a machine learning model in to predict search approvals. The solution included detailed exploratory data analysis (EDA) to uncover stop and search biases. After manual feature engineering making use of geospacial information, a
sklearnpenalized logistic regression optimized with stochastic gradient descent outperformed a set of alternatives, including gradient boosting algorithms. Finally, the model was deployed via a responsiveFlaskAPI endpoint as an accessible application onHeroku. -
Impact: The developed system successfully optimized police search decisions by improving search precision by 5% while reducing biases across minority groups, contributing to fairer and more effective stop-and-search practices.
Click for additional information
- Details and Links: I conducted this case study for the purpose of the Lisbon data science academy (wiki). You can read detailed reports here and here and view the code in the repositories for modeling and deployment.
- Stack:
pandas,numpy,Gradient boosting,XGBoost,scikit-learn,Python,Flask,Heroku,matplotlib,scipy